

Qu’y-a-t-il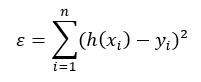 de commun entre la recherche médicale, la création de jeux vidéos, l’analyse de réseaux sociaux, la traduction automatique, la publicité ciblée et la vision par ordinateur ?
de commun entre la recherche médicale, la création de jeux vidéos, l’analyse de réseaux sociaux, la traduction automatique, la publicité ciblée et la vision par ordinateur ?
Derrière tous ces domaines se cache l’usage de l’intelligence artificielle et en particulier une branche de l’intelligence artificielle : l’apprentissage automatique ou machine learning.
L’apprentissage automatique qu’est-ce ?
On peut définir l’apprentissage comme une modification d’un comportement sur la base d’une expérience. Dans le cas d’un programme informatique on parle d’apprentissage automatique ou de machine learning quand ce programme a la capacité d’apprendre sans que cette modification ne soit programmée de façon explicite. Le machine learning est utilisé lorsque les données sont nombreuses mais les connaissances peu accessibles ou peu développées et/ou pour révéler l’importance relative de certaines informations ou la façon dont elles interagissent entre elles pour résoudre un problème.
Que faut-il pour apprendre ?
Le machine learning nécessite deux éléments. D’une part les données à partir desquelles l’apprentissage va pouvoir se réaliser et d’autre part l’algorithme d’apprentissage qui à partir des données va produire un modèle.
Il faut des données d’apprentissage, et plus il y a de données, meilleur pourra être le modèle issu du machine learning. Pour obtenir des données en grand nombre le machine learning s’appuie notamment sur des algorithmes de data-minning. Ce forage de données produira un grand nombre d’objets, ou d’individus, décrits par un ensemble de variables. Le tout sera organisé sous une forme matricielle - terme qui fait référence à la notion de matrices rencontré dans le cours de mathématiques expertes de terminale – que nous appelons également dataframes (langage python : module pandas : voir TP SNT conversion de fichiers trames NMEA en tableaux à double entrée). Les données devront être labellisées (étiquetées) et triées (exclusion des données aberrantes, données manquantes à gérer). Le tri fera donc appel aux notions de moyenne et d’écart-type (intervalle de confiance) pour identifier les valeurs aberrantes, mais pourra également faire appel à la notion d’interpolation (linéaire notamment) pour combler des données manquantes.
Comment apprendre ?
L’un des piliers du machine learning étant de réaliser un apprentissage signalons qu’il existe principalement deux modes d’apprentissage. L’apprentissage supervisé et l’apprentissage non supervisé.
Pour un algorithme d’apprentissage non supervisé toutes les informations disponibles sont considérées comme des entrées. Cet algorithme aura pour objectif de regrouper les objets. Les objets d’un même groupe auront des données similaires et des données différentes correspondront à des objets qui seront dans des groupes différents.
Pour un algorithme d’apprentissage supervisé certaines données sont des entrées et d’autres des sorties. Cette catégorisation est préétablie. Il s’agira ici de faire une prédiction du lien entre données d’entrée et données de sortie soit pour réaliser une classification, création de groupes, soit pour établir une relation entre données d’entrée et données de sortie, relation donnée sous forme d’équation. L’apprentissage supervisé est plus performant que l’apprentissage non supervisé mais nécessite de spécifier une variable de sortie.
Signalons également un autre mode d’apprentissage : l’apprentissage par renforcement. Il s’agit ici d’apprendre un comportement face à diverses situations au cours du temps en optimisant une récompense quantitative (maximiser sa récompense qui doit donc être quantitative pour pouvoir être comparée). L’algorithme, au fur et à mesure de l’acquisition de nouvelles données, déterminera donc régulièrement un nouveau modèle qu’il gardera, ou non, en fonction de la valeur de la récompense.
Apprentissage supervisé :
Abordons, dans le cas de l’apprentissage supervisé, le modèle de régression linéaire univariée, univariée signifiant que nous n’utilisons qu’une seule variable d’entrée.
Nous appellerons X la variable d’entrée, qui prendra les valeurs xi et Y la variable de sortie, qui prendra les valeurs yi pour chacun des objets i du jeu de données.
Il s’agit ici de définir une fonction hypothèse, h, d’estimer ensuite l’erreur produite et enfin de minimiser cette erreur.
La fonction hypothèse, pour une régression linéaire sera de la forme h(x)=ax+b, c’est une fonction affine.
Le problème peut donc se résumer à la recherche du meilleur couple (a,b) pour que h(x) soit proche de Y, la variable cible.
Pour chaque objet, la fonction modèle permet de prédire la valeur de la cible h(xi). L’écart à la valeur cible est alors h(xi)-yi. Certains écarts sont positifs, modèle supérieur à la sortie et d’autres négatifs.
On définit l’erreur unitaire comme étant le carré de cet écart unitaire. L’erreur commise par le modèle est alors :
avec n le nombre d’objets dans le jeu de données.
Si on remplace h par son expression on obtient alors :
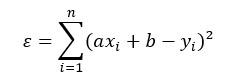
Les valeurs xi et yi sont des valeurs du jeu de données et ne sont donc pas les variables de la fonction. Ce sont a et b les variables de la fonction.
Si a est fixé, la fonction ε dépend de b² et si b est fixé, la fonction ε dépend de a². En fixant un paramètre on peut donc se ramener à une parabole mais la situation dépendant de deux paramètres la représentation graphique de la fonction est à trois dimensions et a une forme de bol très caractéristique.
Chercher à minimiser la fonction ε revient donc à chercher à atteindre le fond du bol.
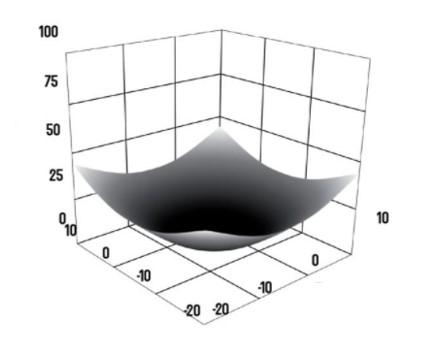
Partant d’un jeu de données initiales (a0,b0), il s’agit de déterminer dans quelle direction, i.e. augmenter ou diminuer les valeurs des paramètres a et b, pour s’approcher du minimum. Il s’agit alors de rechercher la meilleure pente, négative, donc de calculer des valeurs de taux d’accroissement afin de choisir la direction à prendre.
Le calcul se fait de façon itérative jusqu’à approcher le minimum atteint par l’erreur. La vitesse d’approche et la précision de l’approximation du minimum dépendront du choix du pas d’itération.
Et si le modèle n’est pas univarié ?
Dans ce cas il y a plus d’une variable à prendre en compte. La fonction hypothèse dans le cas d’une régression linéaire ressemble encore à une fonction affine mais n’en est plus une, car il y a un nombre plus important de variables et de coefficients a, un coefficient par variable (il reste cependant un seul paramètre b).
On ne peut plus dans cette situation représenter la courbe dans un espace à 3 dimensions mais on réalise le même traitement qu’avec une seule variable d’entrée. L’algorithme demande plus de temps de calcul pour minimiser l’erreur.
Et ensuite ?
Une fois le modèle ajusté aux données d’apprentissage celui-ci pourra être utilisé avec les données à exploiter.
Mais alors…
OUI le monde est mathématiques et je dirais même de plus en plus mathématique. Nous utilisons toutes et tous, directement ou moins directement, consciemment ou plus inconsciemment des outils qui ne pourraient exister sans les mathématiques. Certains d’entre vous auront peut-être reconnu des notations, des notions abordées pendant votre(vos) année(s) de lycée, notions qui constituent le fondement même d’une technologie qui va nous accompagner dans les années à venir.
Pour poursuivre la lecture :
Une présentation sans mathématiques : https://www.technologyreview.com/2018/11/17/103781/what-is-machine-learning-we-drew-you-another-flowchart/
Un exemple très récent de mise en œuvre : https://news.mit.edu/2021/machine-learning-treatment-covid-19-0216